Zero Cost Inference
A brave way to make a prediction is to take a handful of data points and extrapolate it over many decades. In 1965, Gordon Moore had five data points on microchip density over time. He predicted that the number of transistors on a microchip would double approximately every two years. That prediction has held up surprisingly well.
Today, we have a handful of data points on the falling cost of AI inference, partly driven by Moore’s law. Let's make a brave prediction: the long-term cost of AI inference is zero.
There are two key drivers I'm paying attention to:
- Competition drives the cost of hosted inference to near-zero
- Hardware improvements and the emergence of small models drive the cost of local inference to true zero
Competition drives the cost of hosted inference to near-zero
Today, developers have several options to choose from when picking a frontier model. Here is a video showing how models from various providers have quickly converged in quality over the past year.
This fierce competition puts much pressure on hosted inference providers to cut prices to stay competitive. This dynamic is made worse because switching costs for a model are non-existent. With a single line change in a config file, you can switch from GPT-4 to Claude 3. Since output tokens are interchangeable, performance and cost outweigh brand loyalty in this market.
Hardware improvements and the emergence of small models drive the cost of local inference to true zero
I wrote this blog post using a quantized version of Llama 8B running locally on my MacBook via LM Studio.
For writing assistance, the difference in quality between an 8B parameter model running for free on my computer and GPT-4o, was very hard to tell.

This convergence in quality is driven by two trends:
- Mainstream consumer devices now pack enough compute for heavy AI workloads. We tend to take this for granted. My baseline Macbook Air with an M2 chip has an 8-core CPU and an 8-core GPU. Gordon Moore would be shocked by how far his prediction has gone.
- The latest small models now outperform bigger models on various benchmarks. LLama 3 8B performs better than Llama 2 70B — a model with an order of magnitude more parameters.
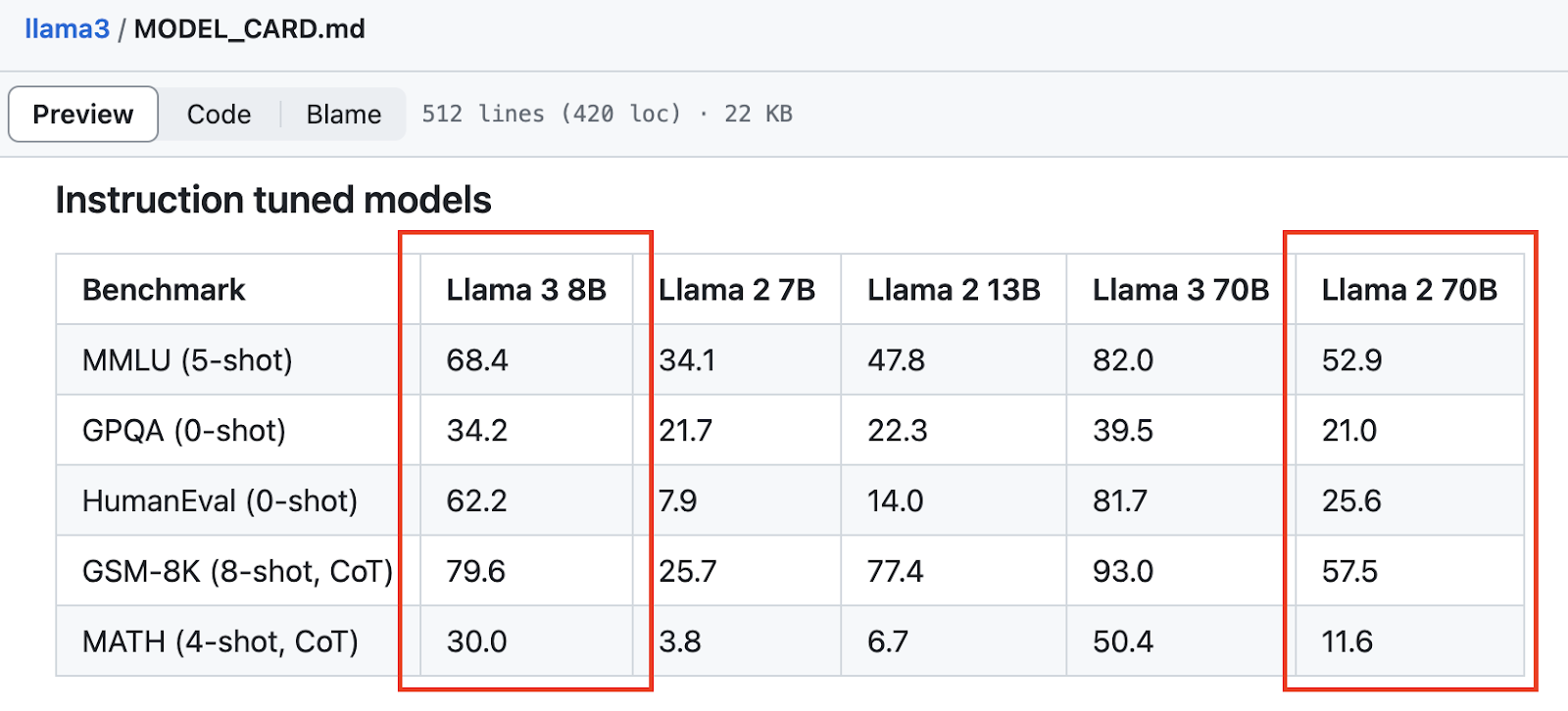
If we marry the trend lines of consumer compute with the emergence of highly capable small models, we start to see how the cost of AI inference falls to true zero.
Zero inference COGS
Zero inference costs unlock a class of products that were previously cost-prohibitive.
For generative apps, inference costs scale with the number of user interactions. This cost structure makes it impractical to build apps that get better with more inference calls. However, those are precisely the apps that provide the most user value. They tend to fall into two buckets: 1) agentic workflows and 2) personalized generative media.
Agentic workflows get better with more inference
It’s a bit intuitive that making multiple calls to a model can dramatically increase agent accuracy. Recent research has made this intuition more concrete with some clever interaction patterns.
In one demonstration, researchers solved various tasks by having different LLM agents generate solutions and debate the solutions of other agents. The results of this "multi-agent debate" were markedly better than those of a single inference call.
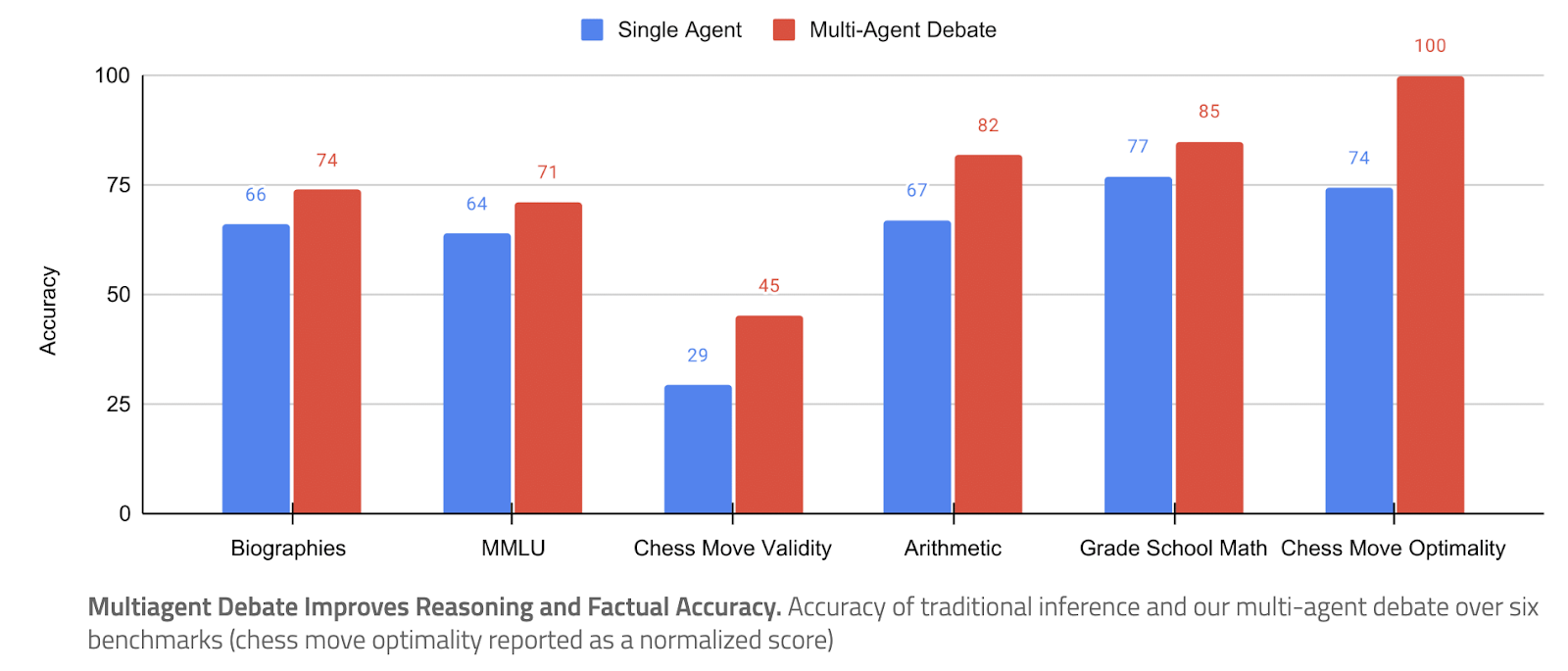
The researchers in this paper limited themselves to three agents and two rounds of debate due to computational cost.
However, this approach seems to have no limit to how accurate it can be.
A team of Google researchers tried to solve competition-level coding tasks with a system called AlphaCode. The accuracy of AlphaCode continued to improve even after a million calls to the underlying model, and this was true across various model sizes (the different colored lines).
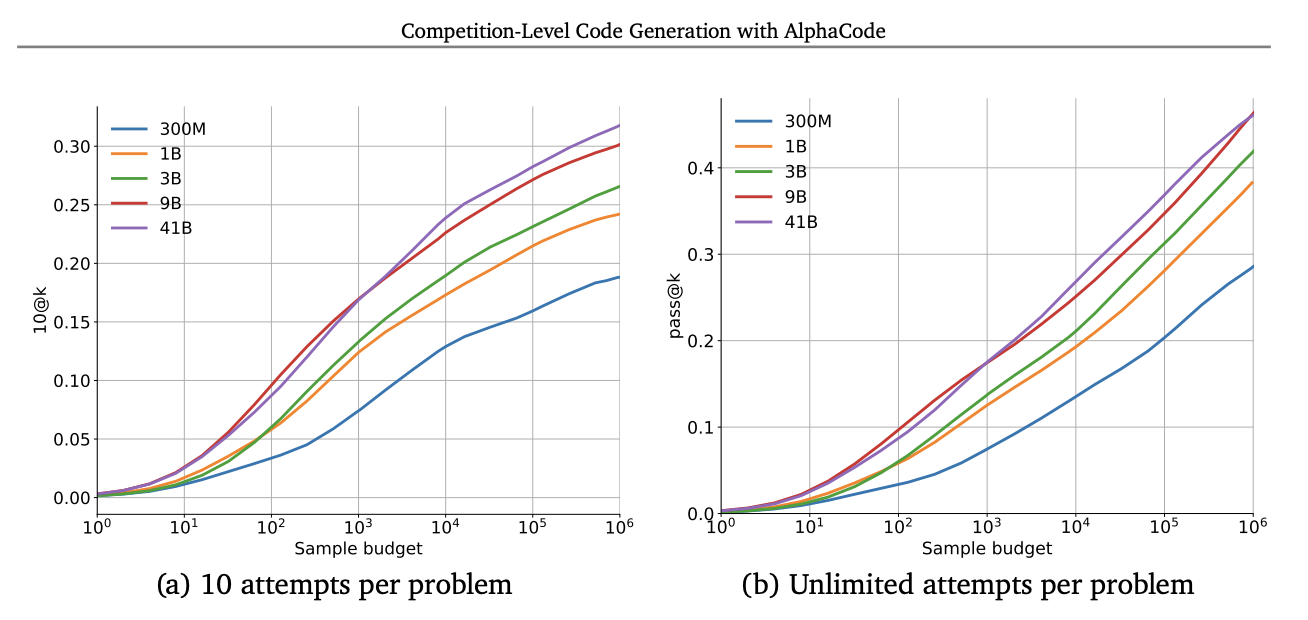
The luxury of making millions of inference calls only exists in a world of free local inference.
Personalized generated media
Fully generated media is another vision of generative AI that is impossible without zero-cost inference. Consider a world where most of the media you consume is fully generated and personalized to you. Perhaps it is interactive, and the narrative path depends on your real-time reaction. In this world, movies and TV shows look more like video games.
What is the daily cost of this vision for the average Netflix subscriber?
The average Netflix subscriber consumes about 60 minutes of video daily. Let’s do some napkin math with the assumption that all of this is generated using today's SOTA models. Runway's Gen-2 model is the most widely available SOTA video generation model. 1 second of video costs $0.01. 60 minutes would cost $36. That's more than your monthly Netflix subscription. The unit economics of streaming would still not work at an order-of-magnitude drop in video generation prices. On-demand video generation only makes sense at zero inference cost.
Local first inference
There’s a prevailing notion that we're on a path towards centralization with frontier model providers forever extracting rents from developers via hosted inference. But, it's becoming clear that you really only need these giant models for the most complex queries.
The future of inference is local first. Apple’s recent WWDC announcement is a great example of this. We'll do as much on-device inference as possible and only use large hosted models when necessary.