Permissions systems
Ever since transitioning to investing, I have been on the lookout for companies that are unlocking greater developer productivity. One pain point I experienced as a developer was setting up and managing permissions for applications. This post dives into why I am excited about new entrants and tools emerging to fill this need. If you are building in this space, I’d love to hear from you.
Not all requests are created equal
Managing permissions as a developer is a tedious task. In my own experience, every time I had to model whether user X could access resource Y or microservice A could access microservice B, was a nightmare of isOwner, isAdmin, isOwnerNotAdmin checks loitering across my codebase and making several requests across many database tables. This got tedious as applications grew in complexity. Implementing a fully-featured permissions system required several developer hours to build and maintain.
Enter: Permissions systems
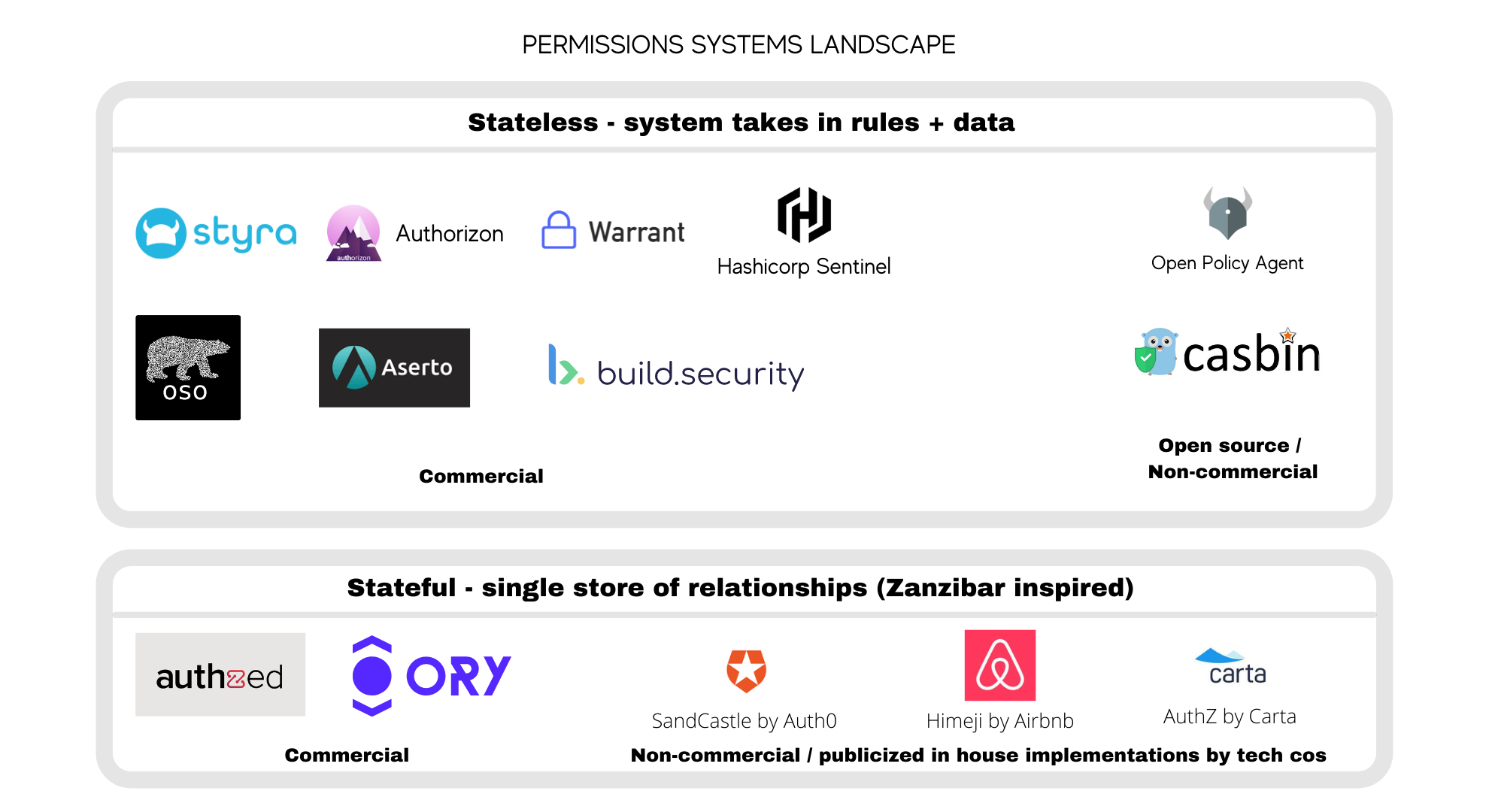
Permissions systems manage the complexity of implementing authorization in your app without you having to reinvent the wheel. They are flexible enough to implement several permissions templates: RBAC, ABAC, ACL. I think of the companies that have emerged to offer permissions-as-a-service products in two buckets based on their underlying implementation:
1) stateless permissions systems
2) stateful permissions systems
Stateless systems
Stateless permissions systems are lightweight implementations that let a developer define rules in a centralized policy engine. This policy engine is then responsible for responding to all authorization requests in the application. They are stateless because a developer must provide both the rules and the data needed to compute a permission to the policy engine.
In this bucket, a number of startups are built on top of Open Policy Agent (OPA), a popular open-source project that has gained significant adoption since coming on the scene in 2016. OPA is a general-purpose policy engine that can be used for everything from authorizing a read/write access request by a user to authorizing a machine-to-machine API call.
Most of the OPA-based startups in this ecosystem are executing on a playbook that provides use case-specific tooling beyond general-purpose needs. For example, Styra, the commercial open source company built by the founders of OPA, provides out-of-the-box Kubernetes admissions controls and an interface for visualizing and monitoring policy decisions. Authorizon, another product built on top of OPA, provides real-time updating of policies via a UI.
Another popular open-source project is Casbin. Other non-OPA based commercial tools include Oso and Warrant — two companies that provide easy-to-use libraries developers can drop into their application.
Stateful permissions systems
A growing approach to managing permissions is to store all the information needed to make a decision in the policy engine. In this approach, a policy engine stores both the rules and the data it needs to make a decision — the engine is stateful. This contrasts with stateless policy engines that have to be given both the policies and all the necessary data required to make a decision.
Stateful permissions systems do not have to query several database rows for the right relationships or hop through several microservices to verify a request. Thus, a decision can be made faster even as the number of permission checks grows.
This approach was popularized by the Google Zanzibar paper. Startups such as Authzed and Ory have sprung up to offer Zanzibar-inspired solutions and are a better fit for latency-sensitive applications. Several tech companies have also publicized their in-house approach including Airbnb Himeji, Auth0 SandCastle, and Carta AuthZ.
Conclusion
Both of these buckets have a few characteristics that make me excited about this category:
- Rules are decoupled from business logic: Offloading permissions to centralized policy engines means that there is a source of truth that decouples policies from business logic. Removing policies from business logic makes it easy to audit, share and update policies across the entire organization. Additionally, developers no longer have to redeploy an entire application every time a policy is updated.
- Services can scale without added policy management complexity: As the number of microservices a team uses grows, complex policies have to be encoded across a larger and larger surface area. A centralized policy engine frees developers from keeping track of rules across multiple services. Services simply make a request to a dedicated policy engine to authorize an action.
- Rules have a software lifecycle of their own: Policy engines typically have a declarative policy language. This allows developers to specify policies as code. Treating rules as code means that developers can now apply engineering best practices such as versioning, automated testing, and CI/CD to the policy codebase.
At Matrix, we’ve been at the forefront of investing in enterprise infrastructure companies and are always excited to meet with folks interested in or building the next generation of enterprise infrastructure tools. If that is you, I would love to hear from you: kojo [at] matrixpartners.com.