Build your own benchmarks
There's no such thing as a good AI model, only a model that is good for your workflow. To see this, you have to build your own benchmarks.
Every major model launch comes with the same kind of benchmark table: MMLU, GPQA Diamond, Humanity’s Last Exam, SWE-bench, and so on. Here is Claude's:
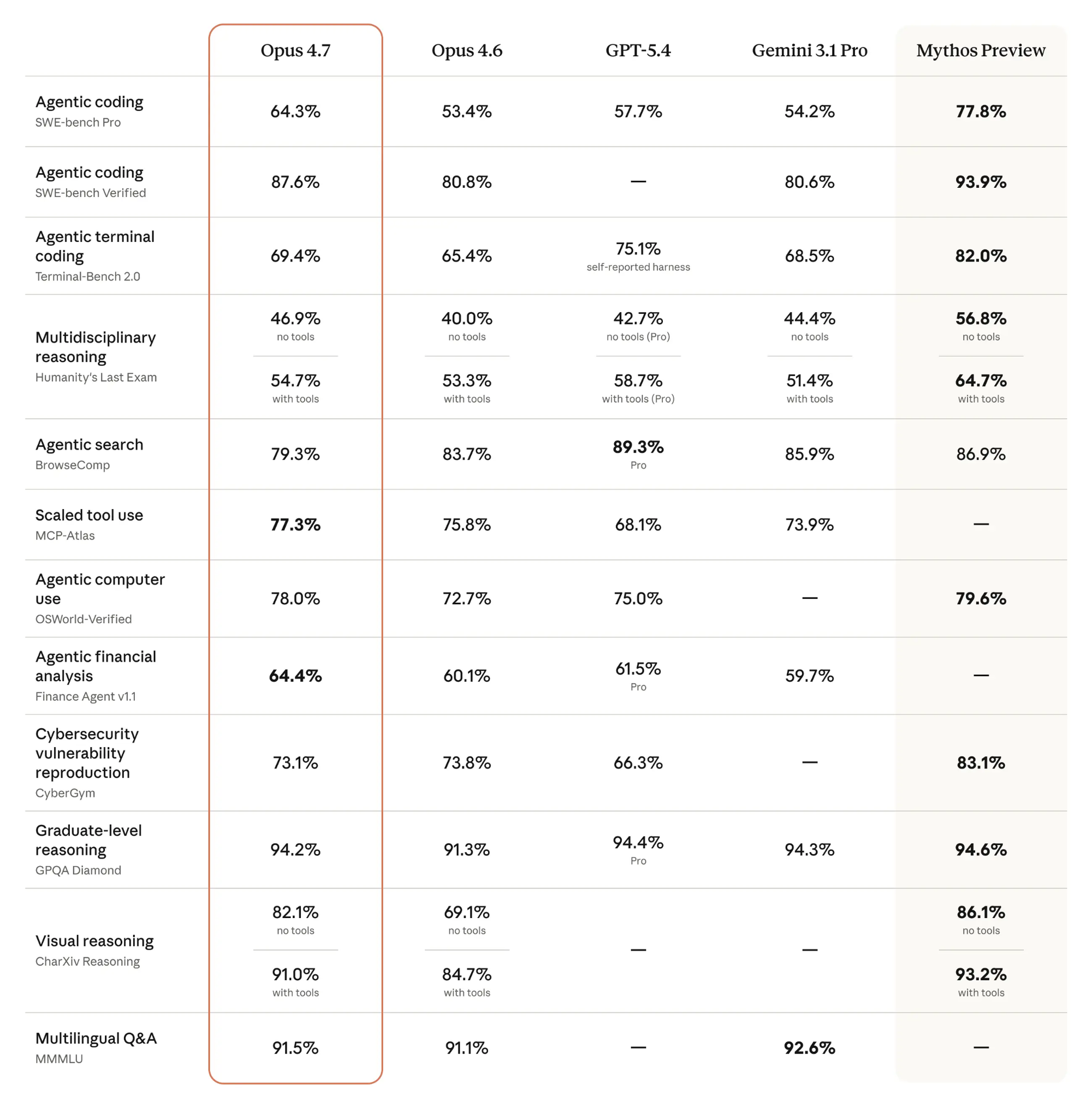
The people who publish these tables, the labs, are building for the widest possible audience and need some way to communicate general-purpose capabilities. But have you actually looked at Humanity's Last Exam? Or GPQA Diamond? If you don't spend your day answering graduate-level physics questions or solving synthetic reasoning puzzles, these benchmarks will feel very foreign. For me, outside of software engineering, it's hard to know what these numbers mean for my day-to-day use of AI models. The implicit assumption is that strong performance on the public table should translate into strong performance for me.
Sometimes it does. Often, it doesn't.
A model can sit near the top of every leaderboard and still feel slightly off for my actual workflow. The opposite happens too. A model that looks worse on the table can be the one I reach for. The vibes are real. They just aren't captured by these public benchmarks.
So how do we pin down the vibes?
The closest I've come is building a benchmark out of my own data. I made a small command line tool called egobench for this. It takes your exported chat history from ChatGPT or Claude, finds recurring task patterns, turns them into a private benchmark, and lets you evaluate different models against it.
I subscribe to a few AI products, and what I've come to like most is having a stable artifact for tracking how models drift over time. Some way to put a finger on whether the vibes for a particular model have really shifted, or whether it's just me.
If you build an egobench benchmark and find something surprising, let me know!